Understanding Flow Matching - A Continuous-Time Generative Framework
Introduction
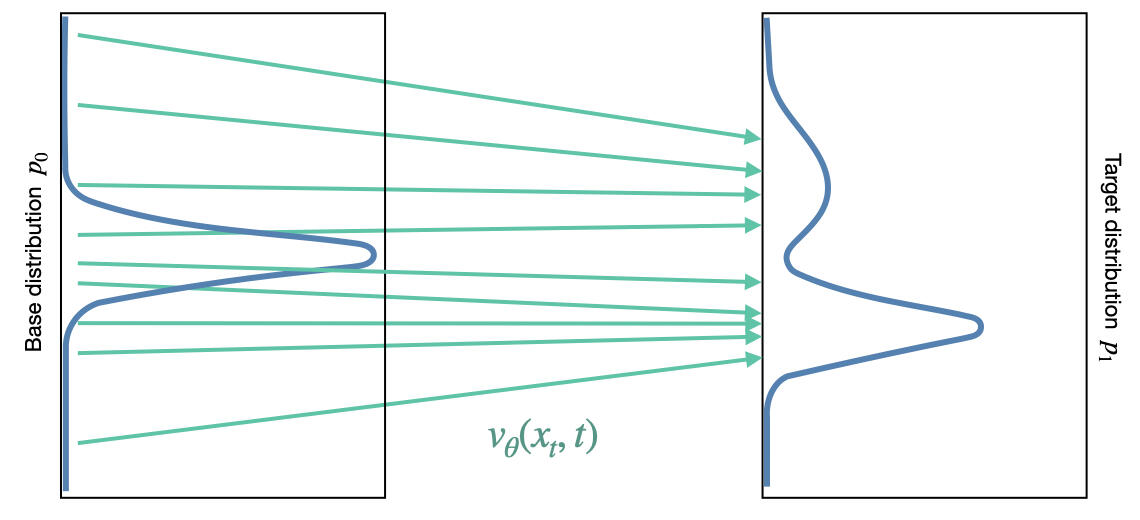
Generative modeling has seen a paradigm shift from the stochastic nature of Diffusion Models to the deterministic elegance of Flow Matching (FM). While Diffusion Models rely on reversing a noise-adding SDE, Flow Matching simplifies the problem by learning a velocity field that pushes a simple noise distribution toward the data distribution along a smooth path.
In this post, we will explore the mathematical framework of Flow Matching and why it is becoming a preferred alternative to traditional diffusion.
Probability Paths and Velocity Fields
Key Definitions and Mappings
To understand Flow Matching, we must first align our physical intuition with mathematical concepts. These concepts are deeply rooted in fluid mechanics and statistical physics.
| Concept | Mathematical Symbol | Physical Intuition | Role in Flow Models |
|---|---|---|---|
| Flow Map | The trajectory of a particle (moving an initial point to a destination). | Inference (Sampling): The path from noise |
|
| Velocity Field | The speed and direction at every position in space at a given time. | Training Target: The neural network |
|
| Density Field | The concentration of particles (probability density) at each position. | Data Distribution: |
|
| Flux Field | The probability mass passing through a unit area per unit time. | Continuity Equation: Describes how probability “flows” through space. |
The Continuity Equation: Understanding Flux
The relationship between the density field
If we define the flux field as
This is identical to the mass conservation equation in fluid dynamics or the charge conservation equation in electromagnetism:
is the divergence of the flux, representing how much “probability flow” is exiting (source) or entering (sink) a point. is the rate of change of density at that point. - Physical Meaning: An increase in density at a location (
) must be balanced by a net inflow of flux ( ). Probability is neither created nor destroyed.
Main Theory
In Flow Matching, we define a time-dependent probability density
- At
, is a simple noise distribution (usually standard Gaussian). - At
, is the complex data distribution .
The transformation of samples from
If we know this velocity field, we can generate data by starting with noise
The relationship between the probability path
This equation ensures that the total probability is conserved as the density “flows” from noise to data.
Our goal is to find the velocity field
Conditional Flow Matching (CFM)
If we try to optimize a neural network to match the true velocity field
Recall that the true time-dependent density field
Because computing
Flow Matching Theorem
To bypass this density bottleneck, we can leverage a beautiful theorem from Flow Matching (Lipman et al., 2022). The core idea is simple: instead of fighting the intractable global distribution, we can break the problem down by conditioning everything on a single, sampled data point
Theorem:
Let
If we define an aggregate, marginal velocity field
Then, this
The Inference Insight: This theorem addresses a fundamental paradox: during training, we can use the knowledge of
to construct simple trajectories, but during inference, does not exist. The theorem proves that if a neural network learns to match the conditional fields on average, it will automatically converge to the true, aggregate velocity field needed for generation.
Proof
We want to prove that the defined velocity field
From the velocity field we defined above, we will derive to this expression:
Multiply by
Take divergence on both sides:
By Leibniz Rule, we can move the
From the conditional continuity equation, we have
Move derivative outside the integral:
The marginal distribution definition is
Finally, we have:
Q.E.D.
Note on Expectation Form: By applying Bayes' rule, we can rewrite the posterior weighting term as
. This allows us to express the complex velocity field as a clean, intuitive conditional expectation over the current state:
Optimal Transport Path & Training Objective
To bridge the gap between abstract theory and scalable training, we must choose a specific conditional probability path
There is a subtle but critical distinction between the theoretical definition and the actual implementation variables. Let
Joint Conditioning
When we condition on both the explicit starting point
In this case, the conditional distribution
Marginal Conditioning on
To satisfy our main Flow Matching theorem, we must treat the starting point
At the boundary
By applying the continuity equation to this moving Gaussian bubble, the true Eulerian velocity field reveals a clear spatial dependency:
As the path approaches the data destination (
Derivation of Particle Path and Regularized Velocity Field
To sample a concrete trajectory point
A Note on Boundary Adjustments: It is worth noting that at
, this regularized path actually samples from rather than a perfect standard Gaussian. However, because is chosen to be incredibly small, this boundary shift is completely negligible in practice, while the numerical safety it grants at is immense.
Now, substituting our regularized mean
Finding a common denominator and grouping terms containing
As
Geometric Intuition: Giving the Data Manifold “Thickness”
Beyond fixing the division-by-zero anomaly, the introduction of
Real-world datasets concentrate on a low-dimensional sub-space—known as the data manifold—embedded within a massive ambient space. Because this manifold has a lower intrinsic dimensionality, its geometric volume (measure) is strictly zero, behaving like an infinitely thin, sharply folded sheet of paper.
If
By adding a tiny bit of noise (
This “thickness” acts as a soft-landing pad, allowing simple ODE solvers (like the Euler method) to safely converge with large, discrete step sizes without drifting into unstable space.
Training Objective
While we have derived the exact formulation for the marginal velocity field
Fortunately, the core Flow Matching theorem provides a beautiful workaround: if we re-introduce the initial noise source
Because the neural network
By using the joint formulation
To address the manifold thickness issue, we can apply a small noise to the interpolated data point:
Sampling Process (Inference)
Generating a new sample is as simple as solving the learned ODE. We start with
ODE Solvers
Because Flow Matching often learns “straighter” paths than the curved trajectories of diffusion models, we can use efficient ODE solvers:
Euler Method: The simplest first-order solver.
Higher-order solvers: Methods like RK4 or adaptive step-size solvers (Dormand-Prince) can achieve high accuracy with very few steps.
Compared to Diffusion Models, Flow Matching typically requires significantly fewer steps (e.g., 10-20 steps) to produce high-quality samples.
Conclusion
The brilliance of Flow Matching lies in its ability to bridge the gap between abstract probability densities and concrete particle trajectories. By reformulating generative modeling as a velocity-fitting problem, it replaces the complex stochastic differential equations (SDEs) of diffusion with intuitive, deterministic ordinary differential equations (ODEs).
This shift offers three transformative advantages:
- Geometric Efficiency: By learning “straighter” paths from noise to data, Flow Matching enables high-quality generation in significantly fewer steps.
- Mathematical Clarity: The training objective is reduced to a simple MSE regression, removing the need for complex ELBO derivations or variance schedules.
- Robustness: Techniques like manifold thickening ensure that the model remains stable even when dealing with high-dimensional, complex data.
As we move toward larger and more capable generative systems, Flow Matching provides a cleaner, faster, and more scalable foundation for the next generation of AI.
- Title: Understanding Flow Matching - A Continuous-Time Generative Framework
- Author: Fireflies
- Created at : 2026-05-21 15:44:34
- Updated at : 2026-07-08 07:17:24
- Link: https://fireflies3072.github.io/flow-matching/
- License: This work is licensed under CC BY-NC-SA 4.0.